AI in SaaS: Add Intelligent Features Without Rebuilding Core
66 Views
Summarize Article

Summarize Article

Key Takeaway: Most AI SaaS teams stall between a working demo and a production-ready feature because they treat AI feature integration as a core codebase problem. It is not. A dedicated service layer adds intelligence to any AI SaaS product fast, without touching what already works.
Fewer than 6% of organizations actually profit from AI despite the vast majority using it across at least one business function. The gap is not about model quality. It is about architectural discipline.
AI SaaS teams that ship reliable, scalable intelligent features treat AI as a separate service layer alongside the core product, not a module embedded inside it. Most teams get this backward, and that decision is why so many AI SaaS launches get stuck between staging and production.
This guide breaks down exactly how AI SaaS teams can add AI SaaS products and add intelligent features fast, without tearing apart core systems or stalling the roadmap.
AI SaaS feature launches fail at the architecture stage, not the model stage. Teams that rebuild core systems to accommodate AI workloads create dependencies that slow every future release and amplify every existing weakness in the product.
The pattern is consistent: every AI SaaS build that misses production. A proof of concept works. Then the team scopes the production version and discovers the existing infrastructure cannot handle async AI calls, variable latency, or governance requirements under real user load. Token costs spike. The roadmap stretches. The feature ships late or degraded.
Standard product prioritization frameworks do not account for what AI feature integration actually adds to a sprint: data readiness requirements, operational cost per call, model reliability under load, and regulatory exposure. Teams using RICE or MoSCoW scoring alone consistently underestimate scope before a single line of code is written.
The adoption-to-execution gap is where most AI SaaS value disappears. Teams demonstrate capability in controlled settings, then hit production environments built for neither non-deterministic outputs nor the governance expectations enterprise buyers carry into every evaluation. The gap widens because teams keep looking for a better model rather than a better container for the model they already have.
This is an architecture problem. SaaS product intelligence roadmaps that treat it as a model selection problem stay stuck indefinitely. The fix is that SaaS product intelligence initiatives that treat it as a model problem stay stuck at the proof-of-concept stage indefinitely. SaaS product intelligence only compounds this gap the longer the wrong diagnosis persists.
The rebuild trap starts when engineering scopes AI feature integration as native functionality inside the core codebase rather than as an independent service that communicates with it. Every AI workload then competes directly with core product stability.
Embedding generative AI SaaS capabilities does not require removing what already works. It requires a thin, controlled layer beside the core. AI SaaS teams that draw this boundary early move faster on every subsequent feature, not slower.
The most reliable path to production-ready AI SaaS features is an API gateway pattern: a dedicated service layer that routes AI calls, handles failures, and manages provider logic without touching the core application backend.
This single architectural boundary gives the team one controlled point to manage every AI feature integration decision: caching, cost monitoring, provider swapping, and fallback logic. The core product stays stable. The AI SaaS layer evolves independently. This is what composable AI architecture looks like in practice, not in theory.
The AI API gateway sits between the UI, the backend, and the model provider. All AI calls route through it. Failures stay contained. Latency spikes do not propagate to core product workflows.
The sidecar pattern places a fully independent AI service beside the main product. If the sidecar goes down, it goes down in isolation. Each AI feature integration stays fully decoupled. This is the standard approach for agentic SaaS feature delivery without system-wide risk.
Async call handling is non-negotiable: LLM responses typically run one to fifteen seconds, and synchronous calls inside a request handler remain the single most common failure point in first-pass AI SaaS integrations.
A standalone vector store plugs into an existing data pipeline and indexes only the information slices the model needs. Core data models stay untouched, but the product gains semantic search, context-rich responses, and embedded AI analytics built on data the team already owns.
This supports retrieval-augmented generation without changing the database schema, the specific blocker most AI SaaS teams hit when scoping SaaS product intelligence features. Strong SaaS product intelligence starts here, not with the model. The vector store handles context. The core database handles everything else.
Each feature below deploys as an independent service communicating with the existing product. None require changes to core logic, database schemas, or authentication systems. All four move the metrics every AI SaaS AI SaaS business tracks: activation, retention, and net revenue retention.
Scope each as a microservice. Build monitoring from day one. Keep failure modes isolated from core product flows. Every AI SaaS team that ships these without a core rewrite follows the same pattern: independent service, async calls, and a clear fallback.
Semantic search replaces keyword matching with intent-aware NLP. Users find answers, not just strings. No changes to the core search schema are required because the feature runs against a vector index built from existing content through LLM integration. The entire deployment is an AI feature integration at the service layer, not a rewrite of the search infrastructure.
In-app content generation via lightweight API calls sits inside current editing or drafting flows, routed through the service layer with no new backend pipelines. Both features improve session depth, task completion rates, and AI SaaS product stickiness, all of which move net revenue retention directly.
Churn prediction models run against usage signals already collected by the product. The AI copilot pattern here operates as a background job: the model processes signals, flags risk scores, and routes alerts to the right team without touching the core support or CRM stack.
AI feature integration at the onboarding layer deploys at the interface level. Contextual hints, progress-based nudges, and intent-aware tooltips read product state and return recommendations through the service layer.
AI SaaS AI SaaS activation rates improve without changing any infrastructure responsible for the core user journey. This is what clean AI feature integration looks like at the onboarding layer.
Quick Glance: What Each AI SaaS Feature Looks Like in Practice

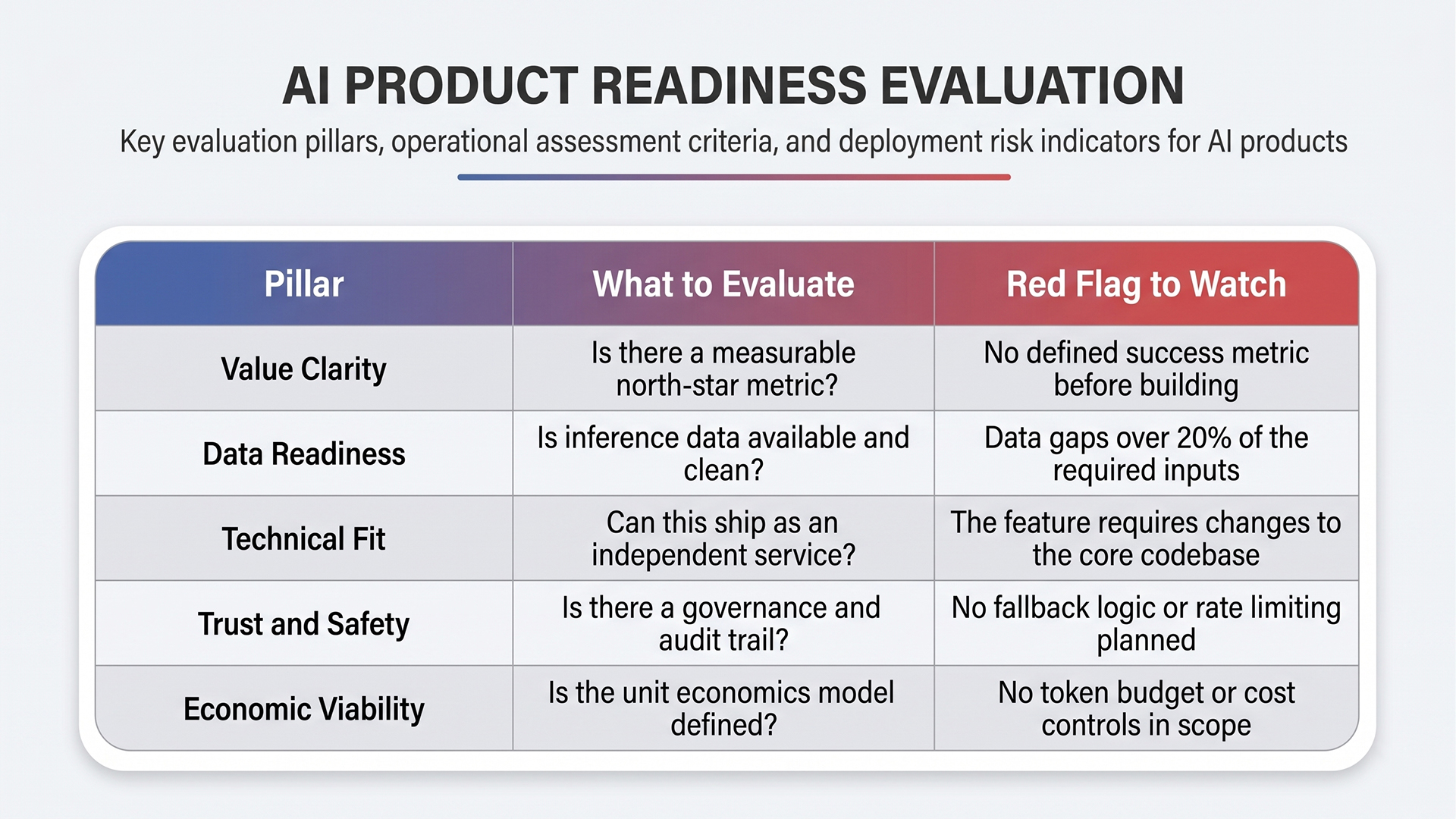
SaaS product intelligence prioritization requires a different model than standard RICE scoring. The five dimensions that matter are value clarity, data readiness, technical fit, trust and safety, and economic viability. Features that cannot pass all five should not reach the build stage in any AI SaaS product roadmap.
Features with no measurable north-star metric accumulate permanent roadmap debt. An open-ended AI scope is where SaaS product intelligence SaaS product intelligence initiatives stall long-term when the scope is open-ended, and that is where engineering hours disappear without shipping anything production-ready.
API-based AI feature integration covering content generation or smart categorization ships faster and costs less than proprietary model development. For commodity AI SaaS AI SaaS features where competitive differentiation is low, buying the model and owning the modular AI orchestration layer is the right call.
Proprietary model development only justifies its cost when the feature drives core competitive differentiation and the data moat is already in place. Most AI SaaS teams at Series A to B should buy the model and control the orchestration layer. AI SaaS
Rate limiting at the user level, monthly token budgets, and input length validation are the three non-negotiable controls for any AI SaaS AI SaaS AI feature integration with non-trivial per-call costs. Without these, a successful AI feature integration launch becomes a cost crisis within weeks.
Placing AI feature integration behind paid tiers serves two functions simultaneously: cost control and a monetization signal. It also generates the usage data needed to design consumption-based or outcome-based pricing for the next stage of the AI product roadmap.
Quick Glance: The Five-Pillar Model for SaaS Product Intelligence Decisions
WebOsmotic builds production-ready AI SaaS feature layers for SaaS and enterprise product teams, starting with a current-state codebase audit that identifies integration points, SaaS product intelligence gaps, and the lowest-risk entry features for each product.
With over 1,000 solutions delivered across healthcare, fintech, logistics, and eCommerce, WebOsmotic has the engineering depth to scope and ship AI SaaS AI SaaS service layers that hold under production load from launch.
Ready to move your AI SaaS product from pilot to production? Start with a WebOsmotic architecture review before the next sprint begins.
The AI SaaS teams shipping durable intelligent features in 2026 treat AI as a service layer decision, not a product feature decision. The architectural boundary between AI workloads and the core product is what makes faster experiments, safer rollouts, and real SaaS product intelligence possible without destabilizing what customers already depend on.
The question is no longer whether to build SaaS product intelligence. It is whether the architecture can handle it reliably and profitably when real users hit it at scale.
If the AI SaaS foundation is right, everything else moves faster. Sit down with the WebOsmotic team for an AI SaaS readiness review before the next sprint cycle.
Yes. Most AI SaaS features deploy through an API gateway or sidecar pattern that sits alongside the existing backend. A dedicated service layer handles routing, caching, and fallback logic without touching core architecture, database schemas, or authentication systems.
An AI service layer is dedicated middleware between the UI, backend, and AI model providers. It handles routing, caching, rate limiting, and provider swapping. Failures stay isolated from the core product, making it the standard architecture for production AI SaaS deployments at scale.
API-based AI feature integration covering content generation or smart categorization typically runs $10,000 to $30,000 in development, with $200 to $2,000 per month in ongoing API costs. Proprietary model development costs more and is only justified when the feature drives core competitive differentiation.
Semantic search, in-app content generation, predictive churn alerts, and AI-assisted onboarding each deploy at the service or interface layer. None requires changes to core logic. All four improve activation and retention metrics that directly affect net revenue retention for AI SaaS products.
The sidecar pattern places an independent AI service beside the core product. If the AI component fails, the failure stays contained in the sidecar. Core functionality stays available. It is the standard approach for AI SaaS teams adding complex features without accepting re-architecture risk.
Use a five-pillar model built for SaaS product intelligence decisions: value clarity, data readiness, technical fit, trust and safety, and economic viability. Features that cannot pass all five should not reach build. Ship one feature, instrument it with telemetry, measure it against a north-star metric, then scale SaaS product intelligence further.


