Retell AI vs VAPI: Which Voice Stack Survives at Scale
55 Views
Summarize Article

Key takeaways
|
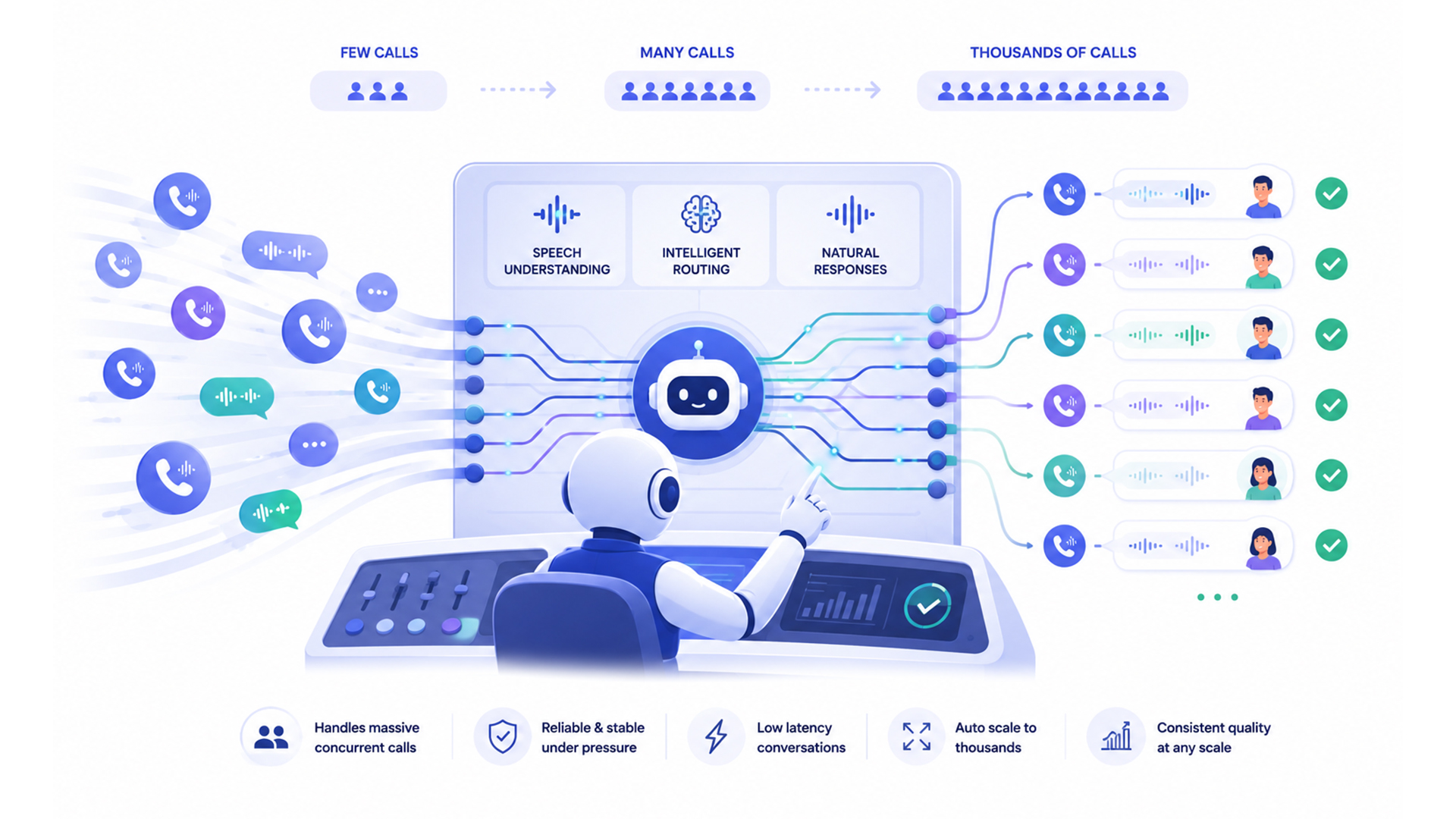
The voice agent platform market is consolidating around a small number of managed pipelines that abstract the STT, LLM, and TTS stack into a single API. Retell AI and VAPI are the two most widely deployed developer platforms in this category in 2025, and the choice between them defines the architecture your team will maintain, debug, and scale.
The AI voice agents market was valued at USD 2.54 billion in 2025 and is projected to reach USD 35.24 billion by 2033 at a 39% CAGR, per Grand View Research. The AI voice generator market sits at USD 4.16 billion in 2025, projected to reach USD 20.71 billion by 2031. MarketsandMarkets notes that achieving consistent sub-200ms real-time speech-to-speech latency remains a major barrier for high-volume environments such as contact centres and automotive assistants.
Neither Retell AI nor VAPI is the automatic winner. The right choice depends on your team’s technical profile, your call volume, your compliance requirements, and which failure mode is more expensive: the failure to customize deeply enough, or the failure to deploy quickly enough.
| Building a voice agent that needs to perform at production call volume? WebOsmotic engineers real-time voice AI systems from STT through LLM to TTS. We evaluate Retell AI, VAPI, and custom stack options against your specific latency, compliance, and scale requirements before any platform commitment. |
Before evaluating platforms, the performance targets need to be anchored to verified standards rather than vendor marketing claims.
Retell AI is a full-stack voice agent platform founded in 2023, Y Combinator-backed, and generating USD 7.2 million in annual revenue with a team of seven people as of its growth stage in 2025. It provides a complete pipeline from telephony to STT to LLM to TTS, with a workflow builder that non-developer teams can use alongside a developer API for programmatic control.
VAPI is a developer-first voice AI platform founded in 2020, Series A-funded with USD 20 million raised, and has powered tens of millions of AI-driven calls with over 150,000 developers onboard. It provides low-latency WebSocket streaming and a highly configurable API, giving engineering teams direct control over the full pipeline.
| Dimension | Retell AI | VAPI |
| Founded | 2023: Y Combinator backed | 2020 : Series A, USD 20M raised |
| Primary audience | Product teams and non-developer operators who need a managed voice agent with a workflow builder | Developer and engineering teams who need fine-grained API control over every pipeline component |
| Customization depth | Configurable within the platform’s managed parameters. Custom model injection is limited compared to VAPI | Bring-your-own STT, LLM, and TTS models. Full API control over pipeline configuration |
| Latency target | Sub-300ms for standard configurations | Sub-300ms via WebSocket streaming; configurable response-speed slider |
| Telephony | Inbound and outbound calling, warm and cold transfers | Global telephony coverage, number pooling, multi-provider routing |
| Compliance | SOC 2 and HIPAA documentation, verify current scope directly with Retell AI | SOC 2 verify HIPAA coverage and data residency documentation directly with VAPI |
| Best for | Healthcare triage, appointment booking, financial services IVR, retail outbound | Developer-built outbound calling, custom model pipelines, high-volume contact centre automation |
| Scale evidence | USD 7.2M ARR with 7-person team as of 2025 growth stage | Tens of millions of calls; 150,000 developers; USD 20M Series A |
ElevenLabs is frequently mentioned alongside Retell AI and VAPI, but it occupies a different position in the stack. ElevenLabs is a text-to-speech synthesis platform, not a full voice agent platform. It can be integrated as the TTS component within both Retell AI and VAPI pipelines, providing expressive, human-like voice synthesis.
The failure modes of managed voice agent platforms are consistent across both Retell AI and VAPI. They do not appear in single-session demos. They appear when call volume grows.
WebOsmotic’s voice AI engineering practice evaluates Retell AI, VAPI, and custom stack options against clients’ specific compliance, scale, and latency requirements before any platform is selected. For clients in healthcare and fintech where compliance documentation is a hard requirement, the platform evaluation includes a formal compliance review before any development commitment.
| Ready to build a voice agent that holds up under real call volume and compliance requirements? WebOsmotic designs and builds voice AI systems for enterprise contact centres, outbound calling programmes, healthcare triage, and fintech automation. Whether you are evaluating Retell AI, VAPI, or a custom stack, we can help you make the right architecture decision first. |
What is the main difference between Retell AI and VAPI?
Retell AI is a full-stack managed voice agent platform built for product teams and non-developer operators who need a guided workflow builder alongside a developer API. VAPI is a developer-first platform with a highly configurable API, WebSocket streaming architecture, and bring-your-own-model support for teams that need fine-grained control over every pipeline component. Both target sub-300ms conversational response and have powered millions of production calls. The choice depends on whether your team’s primary constraint is development speed and guided configuration, or deep technical control and custom model flexibility.
What latency should a production voice agent achieve?
Microsoft’s AI agent performance research establishes three thresholds: 500ms is the psychological threshold for natural conversation, 800ms is the production target for AI voice agents, and 1,000ms is the abandonment threshold where callers hang up 40% more frequently. IBM documents that natural language conversation requires approximately 200ms latency to feel natural. The ITU-T G.114 standard sets 150ms as the upper threshold for high-quality real-time voice communication. The benchmark that matters for platform evaluation is P95 latency at your expected peak concurrent call volume, not average latency in a single-session demo.
Can I use ElevenLabs with Retell AI or VAPI?
Yes. ElevenLabs is a text-to-speech platform that can be integrated as the TTS layer within both Retell AI and VAPI. For real-time voice agents, ElevenLabs Flash v2.5 is the appropriate model at approximately 75ms latency. The Multilingual v2 and v3 models carry 1 to 2 seconds of latency and are not suitable for conversational agents. Geographic latency variance is a production consideration: Flash v2.5 shows 350ms from US East and 527ms from India in end-to-end pipeline testing, which affects teams deploying to callers in regions outside the US East availability zone.
How do I evaluate voice agent platforms before committing?
Four tests matter before committing to any voice agent platform. First, request P95 latency data at your expected peak concurrent call volume, not average latency in a demo. Second, test under noisy audio conditions, accented speech, and telephony compression, which widen accuracy and latency gaps that clean-audio benchmarks conceal. Third, model the cost at your projected call volume to identify the crossover point where a managed platform becomes more expensive than a custom stack. Fourth, verify compliance documentation against your specific regulatory requirements, particularly for HIPAA if you are in healthcare or specific financial services regulations if you are in fintech.
What are the main failure modes of managed voice agent platforms at scale?
Concurrent load latency is the most common production failure: a platform performing at 280ms in a demo may exceed 1,200ms at 500 simultaneous calls. Endpointing failures under real-world audio conditions, including background noise and accents, either cut callers off or add 200ms or more to response time. Cost model surprises emerge when per-minute billing compounds across high call volumes. Compliance gaps become apparent when a platform’s general SOC 2 certification does not satisfy the specific requirements of HIPAA, GDPR, or sector-specific financial regulations.
How does WebOsmotic evaluate voice agent platforms?
WebOsmotic evaluates voice AI platforms against four criteria at the architecture stage: compliance requirements, including HIPAA for healthcare and relevant financial services regulations for fintech; P95 latency requirements at projected peak call volume; cost model at scale, including the crossover point between managed and custom infrastructure; and the team’s capacity to operate platform-level infrastructure versus application-level customization. For most enterprise clients, this evaluation is completed before any platform is selected or any code is written.





