Deepgram vs. Whisper API: which STT is right for real-time AI apps
7 Views
Summarize Article

Summarize Article
Key takeaways
|
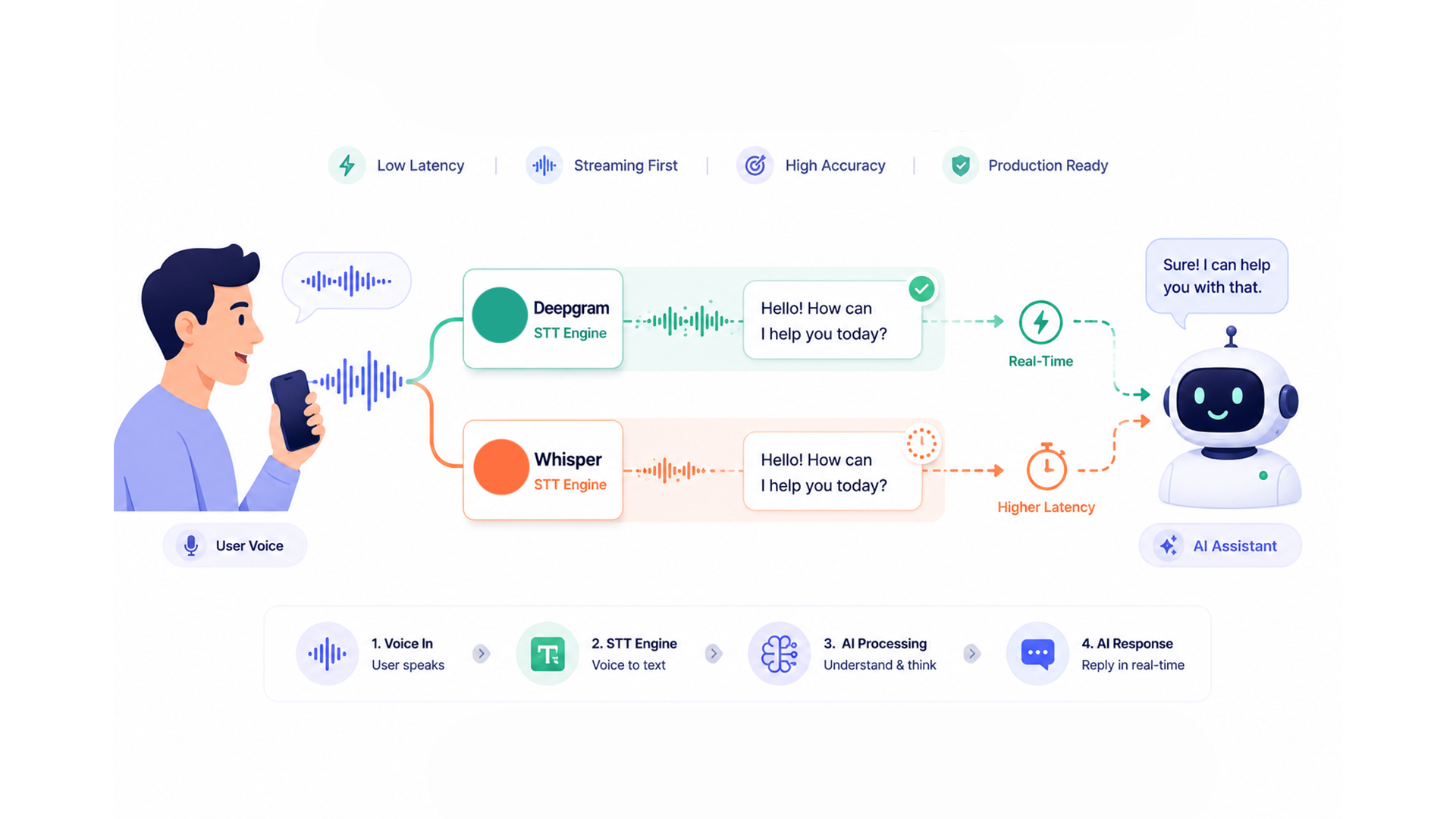
The speech-to-text decision in a voice AI application is the decision that determines whether the agent can hold a natural conversation. Not because transcription accuracy is everything, it is not, but because transcription latency is the first time cost that accumulates before the LLM has received a single token of context.
A voice agent pipeline has four latency stages: speech-to-text, endpointing, LLM inference, and text-to-speech. Each stage adds to the total before the caller hears a response. Microsoft’s AI agent performance research establishes 500ms as the psychological threshold for natural conversation and 1,000ms as the abandonment threshold. An STT layer that adds 300ms leaves 200ms for the remaining three stages at the conversational threshold. An STT layer that adds two seconds makes the target unreachable regardless of how fast the LLM runs.
This post compares Deepgram Nova-3 and OpenAI’s Whisper family, including the newer GPT-4o-transcribe models, across the four production dimensions that matter: latency, accuracy, pricing, and deployment model.
| Building a voice agent that needs sub-500ms end-to-end response? WebOsmotic engineers real-time voice AI systems with STT, LLM, and TTS integrated for sub-second production performance. We evaluate Deepgram, Whisper, and GPT-4o-transcribe against your call volume, compliance requirements, and latency budget before any platform is committed. |
Deepgram Nova-3 is Deepgram’s current-generation speech-to-text model, available through their managed API. It is purpose-built for production voice workloads, with streaming transcription that delivers partial results as audio is received rather than waiting for sentence completion.
Whisper is OpenAI’s open-source speech recognition model, available both as a self-hosted open-source model and as a managed API (the Whisper API on the OpenAI platform). Understanding which version is being evaluated is important because the options carry very different performance and cost profiles.
| Dimension | Deepgram Nova-3 | Whisper (self-hosted or API) |
| Streaming support | Native: sub-300ms partial results during audio capture | No native streaming. Requires chunked processing pipeline that adds seconds of latency |
| Latency for real-time | Under 300ms, compatible with sub-500ms voice agent targets | Self-hosted: often 1-4+ seconds depending on GPU provisioning. API: faster but still no streaming |
| Word error rate | Deepgram claims 36% higher accuracy than Whisper on production audio. Performance maintained across noise, accents, and terminology | Whisper accuracy varies: reviews note it can hallucinate. Performance degrades on noisy audio and specialized vocabulary |
| Pricing (managed) | $4.30 per 1,000 minutes (Nova-3, streaming). Cheapest in the 2025 Artificial Analysis benchmark | $6.00 per 1,000 minutes for Whisper API and GPT-4o-transcribe on OpenAI’s platform |
| Infrastructure burden | Zero: fully managed. No GPUs, no DevOps, no version management | Self-hosted: GPU procurement, DevOps maintenance, version updates, scaling management. API: zero infrastructure |
| Model updates | Deepgram manages model updates. Teams stay on current models without engineering effort | Self-hosted: manual update cycles. OpenAI API: automatic but without streaming for older Whisper versions |
| Domain-specific models | Nova-3 Medical for healthcare audio. Nova-3 Finance and others available | General-purpose only. No domain-specific fine-tuned variants through the API |
| Self-hosted option | Yes: on-premises and VPC deployment available for compliance-sensitive workloads | Yes: open-source self-hosting is Whisper’s primary use case. Adds infrastructure cost and latency versus managed alternatives |
| Best use case | Real-time voice agents, contact center transcription, voice AI pipelines requiring sub-500ms STT latency | Batch transcription of recorded audio where latency is not a constraint; self-hosted deployments where open-source control is required |
Deepgram’s performance advantage in real-time streaming is genuine and well-documented. Whisper’s continued relevance comes from two specific scenarios where its characteristics are advantages rather than disadvantages.
OpenAI’s release of GPT-4o-transcribe in March 2025 changed the Whisper comparison because it replaced the older Whisper Large V2 as OpenAI’s primary transcription offering. GPT-4o-transcribe has lower word error rates than Whisper Large V2, but it inherits several of the same limitations that affect Whisper’s suitability for real-time voice AI.
WebOsmotic builds the voice AI pipeline for clients in logistics, healthcare, and fintech including STT selection, LLM routing, and TTS integration. The STT platform is selected based on latency requirements, audio conditions, domain vocabulary, and compliance constraints for each specific deployment.
| Evaluating STT platforms for a voice AI or contact center application? WebOsmotic selects and integrates STT, LLM, and TTS components for real-time voice AI systems. We test against your audio conditions, compliance requirements, and latency budget before committing any platform in the architecture. |
Is Deepgram or Whisper better for real-time voice agents?
Deepgram Nova-3 is substantially better for real-time voice agents because it provides native streaming with sub-300ms latency. Whisper does not support native streaming, requiring chunked processing pipelines that add seconds of latency. Microsoft’s AI agent performance research establishes 500ms as the psychological threshold for natural conversation and 1,000ms as the abandonment threshold. Whisper’s chunked pipeline latency in real-time applications typically exceeds these thresholds, making it structurally incompatible with production voice agent requirements unless a custom streaming workaround is implemented. For batch transcription of recorded audio where latency is not a constraint, Whisper’s open-source model is a viable cost-effective option.
What is Deepgram Nova-3 and how does it compare to Whisper?
Deepgram Nova-3 is Deepgram’s current-generation managed STT model, designed for production voice workloads with native streaming, sub-300ms latency, and domain-specific variants including Nova-3 Medical. Deepgram’s published benchmarks claim Nova-3 is 36% more accurate and up to 5x faster than Whisper. At $4.30 per 1,000 minutes, it is priced below OpenAI’s Whisper API and GPT-4o-transcribe at $6.00 per 1,000 minutes, per Artificial Analysis benchmark data. Whisper’s advantages are its open-source availability under MIT license, zero licensing cost for self-hosted deployments, and compatibility with teams already standardized on the OpenAI ecosystem.
How much does Deepgram cost vs. Whisper?
Deepgram Nova-3 is priced at $0.0077/minute for streaming ($4.62 per 10 hours) and $0.0043/minute for batch on the Pay As You Go tier. OpenAI’s Whisper API and GPT-4o-transcribe are priced at $6.00 per 1,000 minutes ($0.006/minute). Self-hosting Whisper Large eliminates API costs but introduces GPU infrastructure expense: Deepgram’s benchmark estimates self-hosted Whisper Large at $0.56 to over $1.25 per hour of audio processed on AWS EC2 P4 instances, which can exceed Deepgram’s managed API cost at $0.462/hour.
What is GPT-4o-transcribe and should I use it instead of Whisper?
GPT-4o-transcribe is OpenAI’s March 2025 transcription model with lower word error rates than the older Whisper Large V2. It is the current recommended OpenAI transcription option for accuracy-sensitive batch workloads. However, it inherits Whisper’s lack of native streaming, is 40% more expensive than Deepgram Nova-3, and processes audio at approximately 25% of Deepgram’s throughput speed per Artificial Analysis benchmarks. For teams already using the OpenAI API for LLM inference, GPT-4o-transcribe provides operational simplicity. For teams prioritizing latency and cost, Deepgram Nova-3 outperforms it on both dimensions.
When does self-hosting Whisper make sense?
Self-hosted Whisper makes sense in two scenarios: batch transcription workloads at high volume where GPU infrastructure already exists and per-transcript cost is the primary optimization target, and compliance environments where audio data cannot leave the organization’s own infrastructure and no commercial self-hosted agreement is acceptable. For real-time voice agents where latency is the constraint, self-hosted Whisper typically requires custom streaming infrastructure that introduces significant engineering complexity and latency. Deepgram’s self-hosted option provides similar data sovereignty with a commercial agreement and better latency than DIY Whisper streaming.
How does WebOsmotic choose between Deepgram and Whisper for voice AI projects?
WebOsmotic evaluates STT platform selection based on three variables: latency requirements relative to the overall voice agent pipeline budget; audio conditions including noise levels, accents, and domain-specific vocabulary; and compliance requirements for audio data handling. For real-time voice agents targeting sub-500ms end-to-end response, Deepgram Nova-3 or Deepgram Flux is the default recommendation. For batch transcription workloads where cost is the primary constraint and no real-time requirement exists, self-hosted Whisper V3 Turbo may be appropriate. The selection is made before architecture is committed.





