LlamaIndex vs LangChain for RAG: A Real Decision
42 Views
Summarize Article

Key takeaways
|
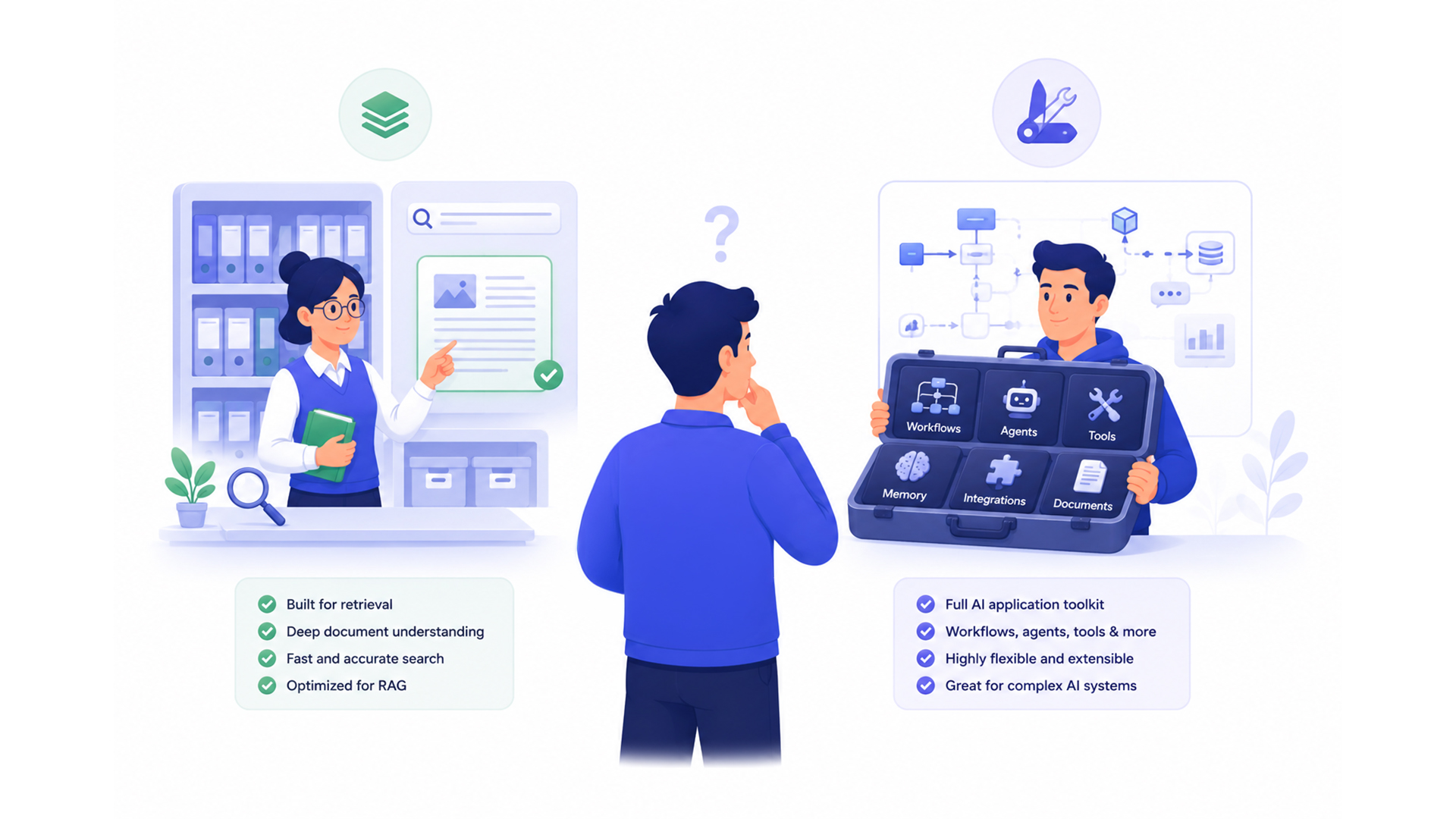
Choosing between LlamaIndex and LangChain for RAG is a question most teams answer incorrectly because they answer it too early. They read a tutorial, pick the framework the tutorial uses, and encounter the limitations of that choice six months later when the hard part of their system is not what the tutorial covered.
The honest comparison is not which framework has better documentation or more GitHub stars. It is which framework’s abstractions align with where the actual complexity in your system lives. For most enterprise RAG systems, that complexity is in one of two places: the document ingestion and retrieval pipeline, or the agent orchestration layer that decides when and how to retrieve.
IBM’s LangChain alternatives analysis positions LlamaIndex as an open-source data orchestration framework that specialises in RAG, enabling developers to index and query structured and unstructured data for AI applications. IBM also notes that LangChain is built around predefined chaining structures that may feel rigid for developers needing customisable workflows, while LlamaIndex is useful specifically for data-heavy applications. That framing is the right starting point.
| Building a RAG system and not sure which framework to start with? WebOsmotic’s engineering team evaluates framework choice against your document types, query patterns, and agent requirements before any code is written. We build production RAG systems for fintech, healthcare, logistics, and eCommerce. |
LlamaIndex was designed from the ground up for the data ingestion and retrieval of half of the RAG problem. Its core abstractions, Documents, Nodes, Indexes, and Query Engines, reflect a data-first philosophy. The framework gives teams precise control over how documents are parsed, how chunks are structured, how metadata is attached, how indexes are built, and how queries are routed to the right retriever.
LlamaIndex’s flagship product, LlamaParse, illustrates this focus. It processes 50-plus file formats, handles complex tables, multi-page layouts, embedded images, and hierarchical document structures that standard chunking approaches fail on. LlamaIndex reports processing over half a billion pages through LlamaParse across enterprise clients including Carlyle, KPMG, and Cemex, and the Salesforce Agentforce team has embedded LlamaIndex heavily into their enterprise RAG infrastructure for parsing and indexing complex data.
LangChain was designed for the agent orchestration half of the AI application problem. Its core value is breadth of integration and ease of wiring components together. The framework provides standard abstractions for model interfaces, prompt templates, tool definitions, memory, and agent loops that let teams connect an LLM to dozens of data sources and services without writing bespoke integration code for each.
The difference between LlamaIndex and LangChain for RAG becomes visible at the edges of the standard use case. For a simple question-answering system over a set of PDFs with clean text, both frameworks work. The divergence appears when the documents are complex, the queries require multi-step reasoning over the index, or the retrieval accuracy requirements are high.
| Dimension | LlamaIndex | LangChain |
| Primary design focus | Document ingestion, indexing, and retrieval accuracy | Agent orchestration, tool use, and workflow chaining |
| Document parsing | LlamaParse handles 50+ file types including nested tables, complex layouts, and images natively | Document loading is available but parsing complex documents requires additional tools or custom code |
| Index flexibility | Multiple index types for different data structures and query patterns | Vector store integration with a standard retrieval chain; less native index variety |
| Query routing | Sub-query engines, query transformations, and routing to multiple indexes are first-class primitives | Retrieval as a tool within the agent loop; less native multi-index orchestration |
| Agent support | LlamaIndex Workflows support multi-agent event-driven systems; agentic document processing is a core product direction | LangChain on LangGraph provides more mature, production-tested agent orchestration with durable state |
| Integration breadth | Strong data connector ecosystem; narrower LLM orchestration integration library | Extensive integrations across models, tools, APIs, and data sources |
| Learning curve for RAG | Higher initial complexity due to richer abstraction layer; payoff is higher retrieval accuracy at enterprise scale | Lower barrier to entry for standard RAG chains; IBM notes documentation is easier for LangChain |
| Enterprise document use | Deployed at Carlyle, KPMG, Cemex, Salesforce for complex document RAG | General-purpose RAG use cases across many industries |
LlamaIndex’s March 2026 post, ‘LlamaIndex is more than a RAG framework’, signals where the platform is heading. The company acknowledges that general-purpose LLM frameworks are less central than they used to be as the industry has matured past needing heavy abstraction layers between developers and models. LlamaIndex’s response has been to double down on the part of the problem they have always owned most deeply: document intelligence and processing.
The cleanest guidance is to match the framework to the primary source of complexity in the system. Most production RAG systems have complexity in more than one place, which is why IBM notes that LangChain and LlamaIndex both provide helper functions to convert Document objects from one to the other, allowing teams to switch between frameworks or combine them at any point in the pipeline.
WebOsmotic’s RAG and AI agent development practice evaluates framework selection as part of the architecture phase for every engagement. For clients in fintech and healthcare with complex document types and strict retrieval accuracy requirements, LlamaIndex is typically the right retrieval foundation. For clients building multi-tool agents where orchestration complexity is higher than retrieval complexity, LangChain on LangGraph is the better foundation.
The RAG framework landscape in 2025 is meaningfully different from 2023, when the LlamaIndex vs LangChain decision was primarily about which project had better documentation and more data source connectors. Three changes have shifted the calculus.
| Ready to choose the right RAG framework for your production system? WebOsmotic builds production RAG systems with LlamaIndex, LangChain, and hybrid architectures. We evaluate your document types, query patterns, and agent requirements at the architecture stage, not after you have already committed to the wrong framework. |
Is LlamaIndex better than LangChain for RAG?
It depends on where the complexity in your system lives. LlamaIndex is better when document parsing and retrieval accuracy are the primary challenges. IBM documents LlamaIndex as the choice for data-heavy applications with complex document types, noting it captures nested tables and complex layouts more accurately than LangChain. LangChain is better when agent orchestration is the primary challenge, when integration breadth matters more than retrieval fine-tuning, and when a lower barrier to entry is valuable. IBM also notes LangChain is easier to use in terms of documentation and vector database integration for standard workloads.
Can LlamaIndex and LangChain be used together?
Yes, and this is often the right answer for complex enterprise RAG systems. IBM’s data ingestion cookbook confirms that both frameworks provide helper functions to convert Document objects from one to the other, allowing teams to switch or combine frameworks at any point in the pipeline. A common production pattern is to use LlamaIndex as the document ingestion and retrieval layer, where its parsing and indexing capabilities are strongest, and LangChain or LangGraph as the agent orchestration layer.
What is LlamaParse and why does it matter for enterprise RAG?
LlamaParse is LlamaIndex’s document parsing service, now handling over half a billion pages across 50-plus file formats. It uses a combination of traditional OCR, computer vision for layout detection, and LLM-based reasoning to handle complex document elements that standard chunking approaches fail on: nested tables, multi-column layouts, embedded images, and hierarchical structures. Salesforce’s Agentforce team uses it for parsing and indexing complex enterprise data. IBM’s data ingestion cookbook found it captures complex tables more accurately than standard LangChain document loading approaches in enterprise document workloads.
What is LlamaIndex Workflows?
LlamaIndex Workflows is an event-driven system for building multi-step processes that combine multiple agents, data connectors, and other tools. It supports reflection, error-correction, and other advanced agent patterns, and can be deployed as production microservices. It represents LlamaIndex’s move from a pure RAG framework toward agentic document processing, combining the retrieval accuracy of LlamaIndex’s core indexing capabilities with multi-agent orchestration for end-to-end knowledge work automation.
How does LangChain handle RAG retrieval?
LangChain treats retrieval as a tool within the agent loop, using vector store integrations and retrieval chains to fetch relevant context. It provides a standard retrieval chain that works with most major vector databases. The limitation for complex RAG use cases is that LangChain’s retrieval abstractions are less specialized than LlamaIndex’s: there is less native support for multiple index types, complex query routing, sub-query decomposition, and the kind of document-level metadata management that high-accuracy enterprise RAG requires.
Which framework does WebOsmotic use for RAG?
WebOsmotic selects the framework based on the primary complexity in the engagement. For clients with complex document types, strict retrieval accuracy requirements, or enterprise document processing workflows, LlamaIndex is the retrieval foundation. For clients where agent orchestration, multi-tool decision-making, and workflow control are the primary challenges, LangChain on LangGraph is the foundation. For systems where both complexities are high, we use LlamaIndex as the retrieval layer and LangGraph as the orchestration layer. The selection is made at the architecture stage, before any implementation begins.





