Agentic RAG vs Naive RAG: What’s Replacing Standard RAG in 2026
54 Views
Summarize Article

Summarize Article

Key takeaways
|
Naive RAG has a single job: chunk documents, embed them, retrieve the top-k most semantically similar chunks at query time, and hand them to an LLM to synthesise an answer. For a narrow set of single-hop questions over a stable, well-structured knowledge base, this works reliably. For the questions enterprises actually ask, it frequently does not.
The failure mode is structural, not incidental. A user asks a question that requires connecting three facts spread across six documents. Naive RAG retrieves the six most semantically similar chunks, which may be six versions of fact one and nothing from facts two or three. The LLM does its best with what it receives and produces a confident, plausible, incomplete answer. The hallucination rate does not spike. The relevance score looks fine. The answer is wrong.
The RAG market reached USD 1.94 billion in 2025 and is projected to hit USD 9.86 billion by 2030, per MarketsandMarkets, growing at a 38.4% CAGR. The majority of that growth is in agentic and adaptive RAG, not in foundational naive approaches. This post maps the architectures replacing naive RAG, explains what each one solves that the previous one does not, and identifies where each still breaks in production.
| Building a RAG system that needs to perform on complex enterprise questions? WebOsmotic architects and builds agentic RAG, GraphRAG, and CAG systems for SaaS, fintech, healthcare, and logistics teams. We design for production accuracy, not demo performance. |
Naive RAG, sometimes called standard RAG or basic RAG, is the retrieve-then-generate pipeline most teams implement first. Documents are chunked into fixed-length passages, embedded into vectors, stored in a vector database, and retrieved by cosine similarity at query time. The retrieved chunks are concatenated into the LLM’s prompt as grounding context.
The limitations are well-documented. Anthropic’s contextual retrieval research identifies the core problem: traditional RAG systems often destroy context. When documents are split into chunks for efficient retrieval, each chunk loses the context of the broader document it came from. A sentence that makes sense in context produces a misleading answer when retrieved in isolation. Anthropic’s contextual retrieval technique, which prepends document-level context to each chunk before embedding, reduces failed retrievals by 49% and by 67% when combined with reranking.
Beyond context loss, naive RAG has four structural limitations that no amount of chunk-size tuning or reranking resolves:
Agentic RAG is the most direct architectural response to naive RAG’s limitations. Rather than a single retrieval pass, agentic RAG embeds AI agents that can plan, iterate, and adapt during the retrieval process itself. Microsoft’s Azure AI Search documentation describes its agentic retrieval as a complete RAG pipeline with LLM-assisted query planning, multi-source access, and structured responses optimized for agent consumption.
The differences between agentic RAG and naive RAG are architectural, not incremental:
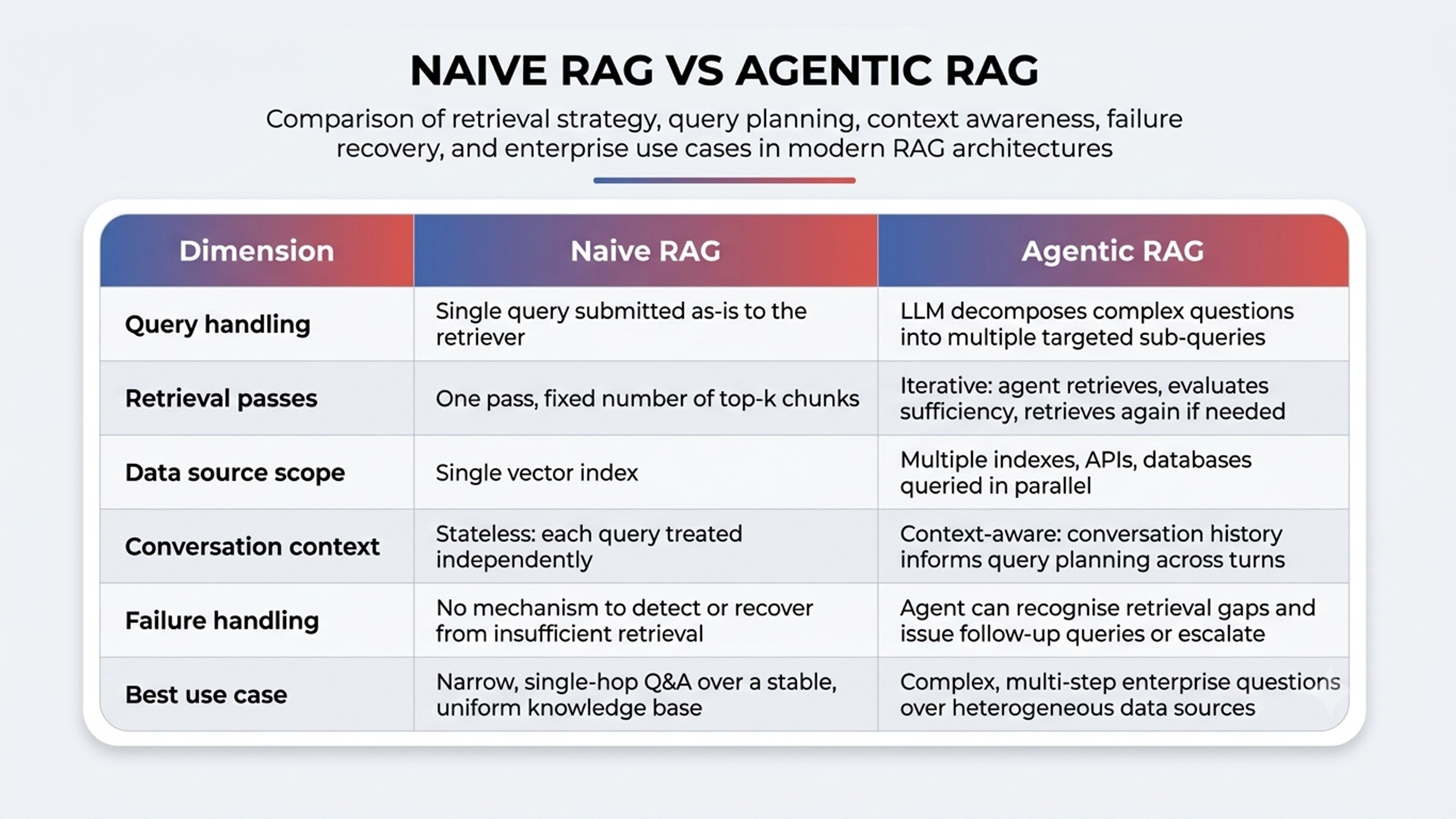
IBM’s agentic RAG pipeline documentation describes the architectural advantage directly: agentic RAG changes the landscape by using domain-specific agents each specialized for specific aspects of retrieval and reasoning, enabling the system to handle technical complexity that approaches human expert reasoning while maintaining automation scalability. For teams building AI solutions across fintech, healthcare, and logistics, this shift from single-pass retrieval to iterative reasoning over multiple sources is the difference between a prototype and a production system.
GraphRAG is a technique developed by Microsoft Research that uses an LLM to automatically extract a knowledge graph from a document corpus, then uses that graph structure to answer questions that require understanding relationships across the entire dataset. It was open-sourced in 2024, is now integrated into Microsoft Discovery, and is available as an Azure-hosted solution accelerator.
The core insight behind GraphRAG is that naive RAG’s vector similarity approach emphasises local paragraph relevance, retrieving chunks that are similar to the query but ignoring the structural relationships between entities across the corpus. For global sensemaking questions, this is a fundamental limitation, not a tuning problem.
GraphRAG’s knowledge graph is built on binary relations: each edge in the graph connects exactly two entities. For many real-world knowledge domains, this is insufficient. Medical facts, legal conditions, financial relationships, and agricultural classifications frequently involve three or more entities in a single relational fact.
HyperGraphRAG, published in peer-reviewed research in 2025, addresses this limitation by replacing binary graph edges with hyperedges that can connect any number of entities in a single relational structure. This allows the knowledge representation to model complex, multi-entity facts without decomposing them into multiple binary relations that lose the original relational meaning.
Cache-augmented generation, or CAG, takes a fundamentally different approach to the knowledge grounding problem. Rather than retrieving relevant chunks at query time, CAG pre-loads an entire knowledge base into the model’s context window at startup. Every query the model handles has access to all documents, all of the time, with no retrieval step.
IBM covers CAG vs RAG as a direct comparison, and Microsoft’s Foundry Local documentation describes it as a pattern for grounding AI models in domain-specific content by pre-loading the entire knowledge base into context at application startup. The tradeoffs between the two approaches are significant:

The commercial relevance for WebOsmotic’s clients in eCommerce and logistics is direct: a pricing engine that needs to reason over a bounded product catalogue, or a compliance tool that needs to reference a complete regulatory rulebook without missing sections, is often better served by CAG than by RAG with its risk of retrieval gaps.
| Not sure whether your use case needs RAG, agentic RAG, GraphRAG, or CAG? WebOsmotic’s AI architects evaluate your knowledge base size, query complexity, update frequency, and latency requirements to recommend the right retrieval architecture before a line of code is written. |
The rapid expansion of LLM context windows, reaching one million tokens and beyond in 2025, has prompted a recurring claim that RAG will become obsolete as context windows grow large enough to hold entire knowledge bases. This framing misunderstands the cost model.
The choice between naive RAG, agentic RAG, GraphRAG, HyperGraphRAG, and CAG is not a technology preference. It is a function of four variables: the size and update frequency of the knowledge base, the complexity and multi-hop nature of the queries the system needs to answer, the acceptable per-query latency and cost, and the relational complexity of the facts the knowledge base contains.

WebOsmotic builds production RAG systems across all of these architectures for clients in fintech, healthcare, logistics, and eCommerce. The architecture decision is made at the discovery stage, before the vector database is selected or the embedding model is chosen, based on a structured assessment of knowledge base characteristics and query patterns.
| Ready to move from a naive RAG prototype to a production-grade retrieval system? WebOsmotic’s engineering team designs and builds agentic RAG, GraphRAG, and CAG systems for enterprise teams. Whether you are starting from scratch or fixing a retrieval accuracy problem, we can help you choose and build the right architecture. |
What is the difference between agentic RAG and naive RAG?
Naive RAG performs a single retrieval pass per query, returning the top-k most semantically similar chunks from a vector index and passing them to an LLM to generate an answer. Agentic RAG embeds AI agents that can decompose complex questions into sub-queries, retrieve from multiple sources in parallel, evaluate whether the retrieved context is sufficient, and perform additional retrieval passes if needed. Microsoft’s Azure AI Search implements agentic retrieval with LLM-assisted query planning and conversation-history-aware context building. The practical difference is that agentic RAG can answer multi-hop questions that naive RAG structurally cannot.
What is GraphRAG and how does it differ from standard RAG?
GraphRAG is a technique developed by Microsoft Research that builds an LLM-generated knowledge graph from a document corpus. Rather than retrieving top-k chunks by vector similarity, GraphRAG traverses the graph structure to answer questions requiring understanding of relationships across the entire dataset. It is particularly effective for global sensemaking questions where the answer depends on patterns or relationships spanning many documents, not a specific retrievable fact. Microsoft Research’s published research demonstrates substantial improvements over naive RAG in comprehensiveness and diversity for this class of questions. GraphRAG is available open-source and through the Microsoft Azure platform.
What is cache-augmented generation and when should it replace RAG?
Cache-augmented generation, or CAG, pre-loads an entire knowledge base into the model’s context window at startup, eliminating per-query retrieval entirely. IBM and Microsoft both document CAG as a direct alternative to RAG for bounded, stable document sets. CAG is the right choice when the knowledge base fits within the model’s context window, when retrieval gaps are unacceptable, and when the knowledge base does not change frequently. It is not suitable for large or frequently-updated knowledge bases because context must be rebuilt when documents change and per-query token costs scale with context size.
What is HyperGraphRAG?
HyperGraphRAG is a research-stage RAG technique published in 2025 that extends GraphRAG by replacing binary graph edges with hyperedges that can connect any number of entities in a single relational structure. This allows it to model complex, multi-entity facts without decomposing them into multiple binary relations that lose relational meaning. Benchmarks across medicine, agriculture, computer science, and law show HyperGraphRAG outperforming both standard RAG and GraphRAG in answer accuracy and retrieval efficiency. As of 2025, it is a research technique with publicly available code but limited enterprise-grade tooling compared to Microsoft’s GraphRAG platform.
Will large context windows make RAG obsolete?
Not in the near term, and not for large enterprise knowledge bases. The cost of placing a large knowledge base into the context window for every query is substantially higher than a targeted retrieval call that fetches the most relevant content. For bounded, stable knowledge bases where completeness is critical, using a long context window, essentially a CAG approach, is a valid and deliberate architectural choice. For knowledge bases of millions of documents, dynamic content, or high query volume, RAG remains the more cost-effective architecture. The correct framing is not long context versus RAG but which retrieval and grounding architecture fits the specific knowledge base.
How does WebOsmotic help with RAG architecture decisions?
WebOsmotic evaluates four variables at the discovery stage: knowledge base size and update frequency, query complexity and multi-hop requirements, acceptable per-query latency and cost, and the relational density of the domain knowledge. Based on that assessment, we recommend and build the appropriate architecture, whether that is agentic RAG, GraphRAG, CAG, or a hybrid approach. We work with teams in fintech, healthcare, logistics, and eCommerce across India and the US, and the architecture decision is made before any vector database or embedding model is selected.



: the integration standard every AI team needs now")

