Your Voice Agent Sounds Robotic Because of This Latency Bug
62 Views
Summarize Article

Summarize Article
Key takeaways
|
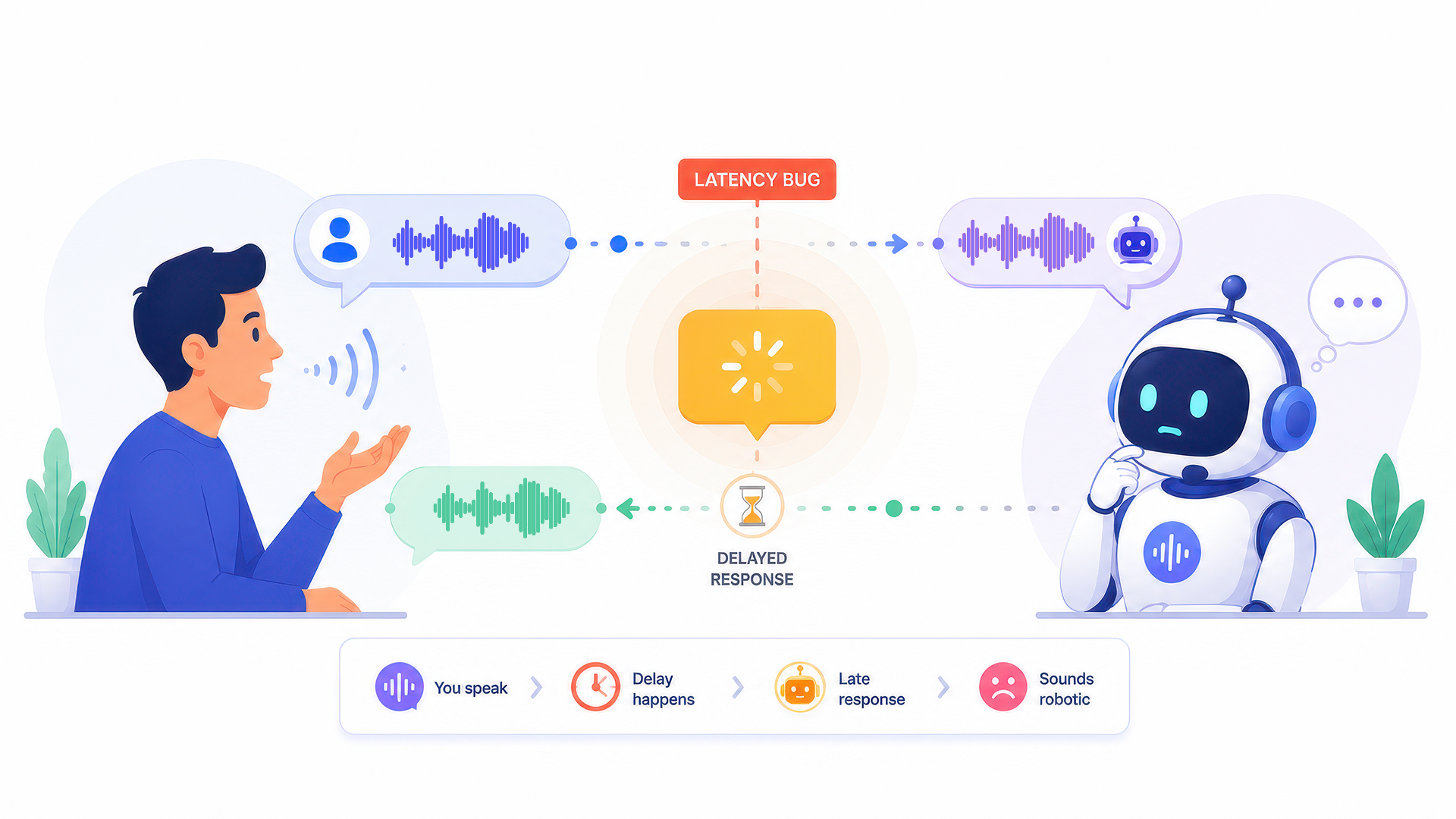
The demo sounds great. A developer calls the voice agent, asks a question, and the response comes back crisp and fast. Then the agent goes to production. Call volume climbs. A caller in a contact centre hears a pause that stretches past a second, then two. The agent sounds robotic. Callers start hanging up. The engineering team starts looking at logs.
Latency is not a single bug. It is a pipeline problem. A voice agent built by chaining a speech-to-text service, a large language model, and a text-to-speech synthesiser from separate vendors accumulates delay at every handoff. Each component performs adequately on its own. Together, under load, they add up to an experience that callers do not tolerate.
The global AI voice agents market was valued at USD 2.54 billion in 2025 and is projected to reach USD 35.24 billion by 2033, per Grand View Research. In a market growing at that rate, the engineering teams that solve voice agent latency at the infrastructure level will have a structural advantage over those still debugging it in production.
| Building a voice agent that needs to perform under production load? WebOsmotic engineers real-time voice AI systems from STT through LLM to TTS, architected for sub-second latency from day one rather than optimized after callers start complaining. |
Before debugging a voice agent pipeline, it is worth establishing what the baseline expectation actually is. The International Telecommunication Union’s ITU-T G.114 recommendation sets 150ms as the maximum one-way delay threshold for high-quality real-time voice communication. This standard predates AI voice agents but remains the reference point against which all voice latency is measured.
AI voice agents operate above this baseline by design. They are not carrying raw voice over IP but processing speech, reasoning over it, and synthesising a new response. The question is not whether an AI voice agent adds latency but how much it adds before the experience degrades to the point where callers notice and disengage.
Microsoft’s research on AI agent performance identifies the key thresholds:
A voice agent latency problem is almost never caused by one slow component. It is caused by four components, each performing within acceptable individual bounds, whose delays accumulate into an experience that fails the 500ms threshold. Understanding where each millisecond comes from is the first step to knowing where to optimize.

Under optimal single-session conditions, this pipeline adds up to roughly 500ms. Under real-world concurrent load, with noisy audio, longer prompts, and geographic variance, the same architecture can exceed one second without any individual component failing. The robotic feeling callers report is not latency, it is cumulative latency, and it requires a pipeline-level fix, not a component-level tweak.
Deepgram and ElevenLabs are the two most widely referenced infrastructure components in independent voice agent pipelines. Understanding their performance characteristics helps teams decide whether to chain them together or move to a unified platform.
Retell AI and VAPI are the two most widely deployed developer platforms for building production voice agents. Both abstract the STT, LLM, and TTS pipeline into a managed layer, and both target sub-300ms conversational response. The architectural differences between them have practical implications for how latency is managed at scale.
For WebOsmotic’s clients building outbound calling agents in logistics and eCommerce or inbound triage agents in healthcare, the platform decision is made at the architecture stage, not after go-live. Latency requirements, call volume projections, and compliance needs are all inputs to the selection decision before the first line of code is written.
| Selecting the wrong platform is the most expensive voice AI mistake WebOsmotic’s engineers evaluate STT, LLM, TTS, and platform combinations against your specific call volume and latency requirements before the architecture is committed. We build voice AI for contact centres, logistics dispatch, healthcare triage, and fintech across India and the US. |
Sub-second voice agent latency is achievable in production. It requires architectural decisions made before the first component is selected, not optimizations applied after callers start dropping. The following principles separate production-grade voice AI from demo-grade voice AI.
WebOsmotic’s AI development practice includes end-to-end voice agent engineering for teams in logistics, fintech, healthcare, and eCommerce. The engagements cover STT selection and configuration, LLM prompt optimization for voice latency, TTS integration, telephony routing, and the end-to-end testing framework that validates P95 latency before a single production call is made.
The teams that commission voice AI from WebOsmotic are not looking for a demo. They are building agents that handle thousands of calls per day across inbound support, outbound qualification, and automated dispatch. For those use cases, sub-second latency is not a premium feature. It is the baseline requirement for a product that callers will actually use rather than immediately escalate to a human.
| Ready to build a voice agent that holds up under real call volume? WebOsmotic designs and builds real-time voice AI systems for production environments. Whether you are starting from scratch or fixing a latency problem in an existing agent, our engineering team can help you reach sub-second performance at scale. |
What is considered acceptable voice agent latency for production use?
The international benchmark is set by ITU-T G.114, which establishes 150ms as the threshold for high-quality one-way voice communication. For AI voice agents, which add processing stages on top of raw transmission, the production target is 800ms or less end-to-end. Microsoft’s AI agent performance research identifies 500ms as the psychological threshold for natural conversation, and 1,000ms as the abandonment threshold where callers begin hanging up at significantly higher rates. Sub-500ms is achievable in production with unified pipeline architecture and streaming at every stage.
Why does my voice agent sound natural in the demo but robotic in production?
Demo conditions rarely replicate production conditions. In a demo, there is typically one caller, clean audio, a short prompt, and no concurrent load on the LLM or TTS service. In production, multiple concurrent calls compete for inference capacity, audio quality varies, and prompts accumulate conversation history. Each of these factors pushes latency upward. The robotic feeling is almost always cumulative pipeline latency exceeding 500ms, not a single slow component. The fix requires measuring P95 latency under your actual call volume, not average latency in a controlled test.
What is the difference between Retell AI and VAPI for voice agent development?
Both are developer platforms that abstract the STT, LLM, and TTS pipeline into a managed layer for building production voice agents. Retell AI is a full-stack platform with strong configuration control over model selection and conversational behaviour. VAPI is a developer-first platform with low-latency WebSocket streaming and a highly configurable API suited to teams that need precise control over response speed and telephony routing. The meaningful difference for production deployments is how each platform performs at your specific concurrent call volume. Neither platform’s demo latency is a reliable predictor of P95 production latency. Both have powered tens of millions of production calls, and the right choice depends on your call volume, compliance requirements, and infrastructure preferences.
Does using ElevenLabs TTS in a voice agent add significant latency?
It depends on the ElevenLabs model selected. Flash v2.5 targets approximately 75ms latency and is designed for real-time voice agent use cases. The Multilingual v2 and v3 models, optimized for expressiveness and voice quality, carry one to two seconds of latency, making them unsuitable for conversational agents. Beyond model selection, ElevenLabs TTS latency increases with geographic distance. Independent testing shows the same model running at 350ms from US East and 527ms from India. For production deployments serving callers in multiple regions, this geographic variance needs to be tested and factored into architecture decisions before the platform is committed.
What does Deepgram STT contribute to the voice agent pipeline?
Deepgram handles the speech-to-text stage of the voice agent pipeline. Its Nova-2 model delivers sub-300ms latency with streaming partial transcripts, which allows the downstream LLM call to begin before the caller has finished speaking. Deepgram also provides a unified Voice Agent API that combines STT, orchestration, and TTS in a shared runtime. This unified architecture reduces end-to-end latency to 200–250ms by eliminating handoff delays between separate transcription and synthesis services, compared to 500ms or more when separate vendors are chained together.
Can WebOsmotic build a voice agent with sub-second latency for our contact centre?
Yes. WebOsmotic builds production voice AI systems for contact centres, logistics dispatch, healthcare triage, and fintech applications. The engagement covers STT and TTS platform selection based on your call volume and geographic distribution, LLM prompt engineering for voice latency, streaming configuration at each pipeline stage, telephony routing optimization, and end-to-end P95 latency validation before go-live. The goal is a system that performs at sub-second latency under your peak concurrent load, not just in a single-caller demo. You can start the conversation via the contact page.



: the integration standard every AI team needs now")

